Inledning
I den första delen av den här bloggserien utforskade vi Protective MBR och dess roll när det gäller att säkerställa att moderna GPT-partitionerade diskar är kompatibla med äldre system. Vi fördjupade oss i hur Protective MBR fungerar som en barriär för att förhindra äldre system från att misstolka GPT-diskar och därigenom säkerställa att hela disken markeras som använd av GPT. Denna grundläggande förståelse skapar förutsättningar för en djupare dykning in i hjärtat av GUID Partition Table (GPT) själv - GPT Header.
I den här andra delen går vi igenom GPT Header, en viktig komponent i GPT-schemat som ger viktig information om diskens struktur. Vi kommer att undersöka varje fält i GPT-huvudet, förklara dess betydelse och hur det bidrar till diskens övergripande funktionalitet och integritet. I slutet av detta inlägg kommer du att ha en omfattande förståelse för GPT-huvudet, så att du med säkerhet kan analysera och manipulera GPT-partitionerade diskar i kriminaltekniska utredningar eller dataåterställningsscenarier.
Översikt över GPT-huvuden
GPT-huvudet (GUID Partition Table) är en viktig komponent i diskens partitioneringssystem. Den delar in disken i separata sektioner som var och en kan lagra olika typer av data, t.ex. operativsystem, personliga filer, programdata eller spel. Dessa sektioner kan vara olika enheter (t.ex. C:-enheten, D:-enheten, E:-enheten etc.).
GPT Header innehåller en säkerhetskopia i slutet av disken, ungefär som att ha en reservnyckel till bibliotekskatalogen ifall huvudnyckeln försvinner eller skadas. Detta säkerställer att vi kan hitta och komma åt våra data även om något går fel.
GPT-huvudet anger platsen för säkerhetskopian och platsen för GUID Partition Table Entry Array, som är en lista över GPT-partitionsposter som anger var dessa sektioner (partitioner) finns på disken.
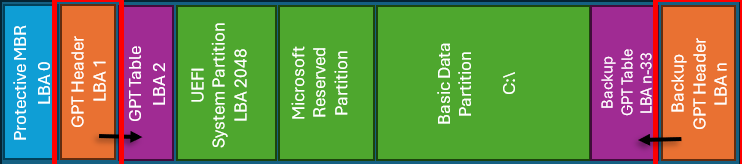
Figur 1: Layout för en hypotetisk Windows 10-installation med en volym (n = sista sektorn på hårddisken)
GPT-huvudet börjar med sin signatur, EFI PART. Resten av värdena är uppdelade i tabellen nedan:
Struktur för GPT-huvuden
GPT Header börjar med sin signatur, "EFI PART." Resten av värdena är uppdelade i tabellen nedan:
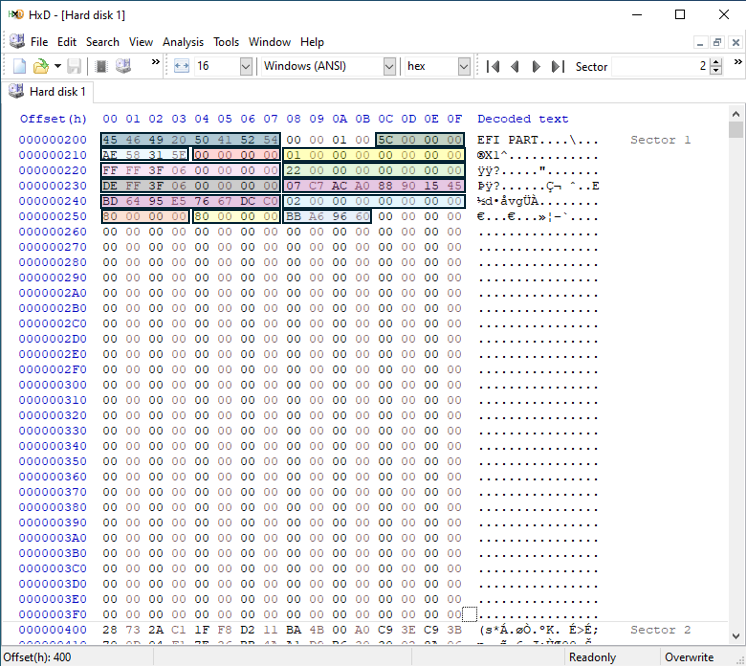
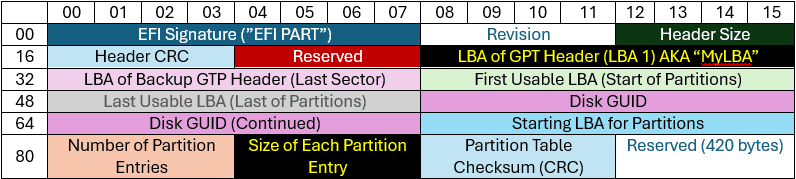
Källa: https://uefi.org/specs/UEFI/2.10/05_GUID_Partition_Table_Format.html

Hittills har de första 16 byte i GPT-headern förblivit konstanta mellan olika GPT-diskar.
CRC för GPT-huvud

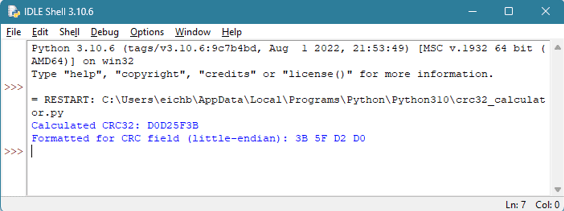
Nedan följer ett exempel på hur du beräknar CRC32 för GPT-huvudet:
Du kan använda ett Python-skript för att beräkna CRC för isolerade byte:

Python-skriptet finns tillgängligt på https://github.com/eichbaumj/Python

Python-skriptet tar det resulterande CRC32-värdet och konverterar det till det format som krävs för GPT-huvudet. Det beräknade värdet är i det här fallet 0x1B2C37BC. Men för att lagra det i fältet i GPT-huvudet läses värdet med liten endian: 0xBC372C1B.

Diskens GUID

I skärmdumpen nedan visas GUID markerat i GPT-headern:

GUID är ett hexadecimalt värde på 16 byte, men om du tror att du bara kan kopiera värdena och separera dem på lämpligt sätt med bindestreck och sätta hakparenteser runt dem, så har du fel. Du skulle få fel värde.
Du kan se att HxD tillhandahåller GUID-konverteringen i datainspektören till höger. Men hur går det till? Hur går det till:
55 BA 55 51 2B D8 59 41 BC 1F C4 17 80 0F D7 63
Bli:
{5155BA55-D82B-4159-BC1F-C417800FD763}
GUID-format
XX XX XX XX | XX XX | XX XX | XX XX | XX XX | XX XX XX XX XX XX
55 BA 55 51 | 2B D8 | 59 41 | BC 1F | C4 17 80 0F D7 63
Den första uppsättningen av fyra byte konverteras till little-endian hex: 51 55 BA 55
Den andra uppsättningen om 2 bytes konverteras till little-endian hex: D8 2B
Den tredje uppsättningen om 2 byte konverteras till little-endian hex: 59 41
De återstående två uppsättningarna av hex-värden lämnas som de är, big-endian: BC 1F | C4 17 80 0F D7 63
När alla konverteringar är klara kan vi sätta ihop dem, placera bindestreck där de behöver vara och omsluta det med hakparenteser:
{5155BA55-D82B-4159-BC1F-C417800FD763}
Vi kan bekräfta att detta är den korrekta kodningen av GUID genom att starta diskpart från kommandoraden och kontrollera diskens unika ID:


GPT-partitionstabell Checksumma CRC

Vi kan använda samma Python-skript men ersätta hex-värdena med de som finns i Partition Entry Array.


Och vi kan se att värdet motsvarar det som finns i GPT-headern.
Reparera en GPT-huvudenhet
Nu när vi vet hur GPT-headern är uppbyggd och att det finns en säkerhetskopia i diskens sista sektor, hur går vi då tillväga för att reparera GPT-headern om den skulle bli skadad eller raderad?
För att reparera GPT-huvudet kopierar du de sista 512 byte från slutet av disken och klistrar in dem i LBA 1 (sektor #2). Observera att några modifieringar är nödvändiga.
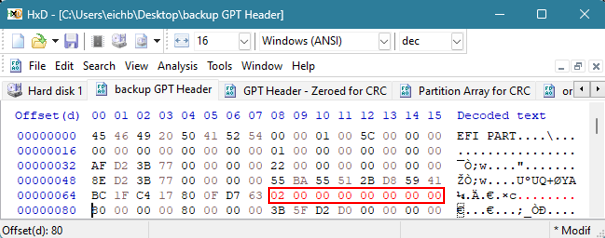
Nedan visas ett exempel på hur GPT-headern för säkerhetskopiering ser ut i slutet av en disk:
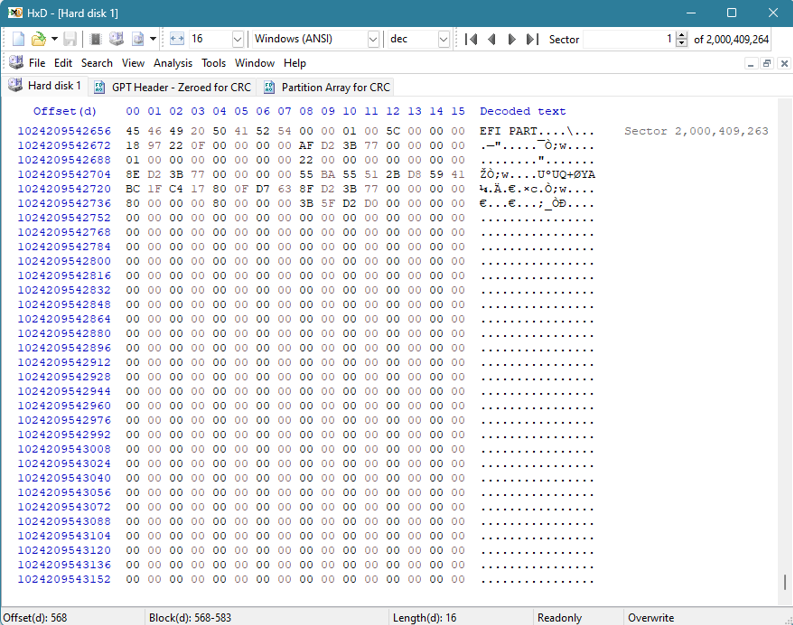
Vi kan se att vissa värden förblir konstanta jämfört med den ursprungliga GPT-headern. Dessa konstanter är markerade med rött nedan:
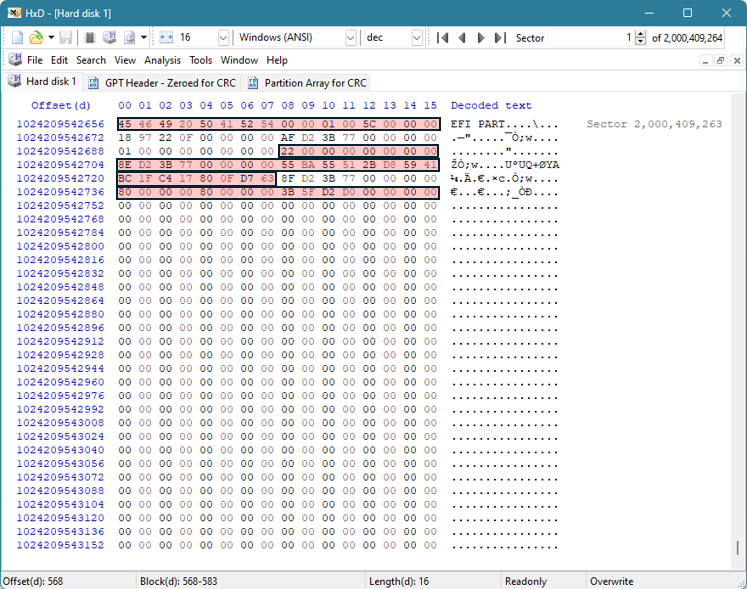
Det finns fyra värden som behöver ändras.
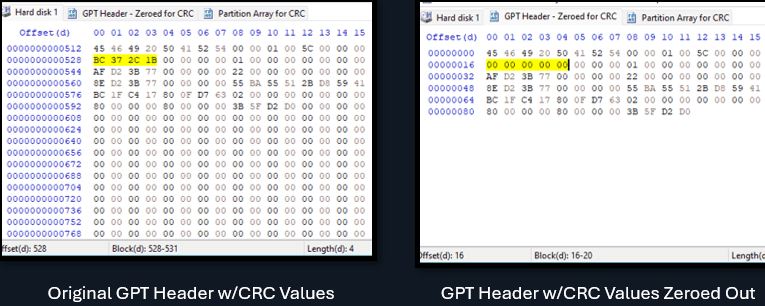
Den första är GPT Header CRC, som vi kommer att återkomma till. För tillfället kan dessa värden nollställas eftersom vi måste använda den CRC som beräknas efter att vi har modifierat de andra värdena för att få rätt CRC igen.

Nästa är MyLBA-värdet som ligger vid offset 24 i 4 byte. Det här värdet pekar på platsen för GPT-huvudet (där det finns för närvarande) och dess nuvarande position är LBA 1 eller 0x01000000000000000.

Värdet på 8 byte vid offset 32 är det värde som pekar oss till platsen för GPT-headern för säkerhetskopian. Säkerhetskopian pekar för närvarande på originalet, men vi måste ändra detta värde för att representera den sista sektorn på disken. Detta hände med de hexadecimala värden som vi just ändrade i föregående steg. I det här exemplet skulle värdet behöva ändras till 0xAFD23B7700000000.
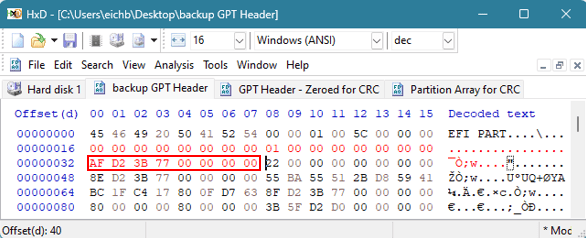
Det 8-byte-värde som finns i offset 72 måste återspegla platsen för och starten på GPT Partition Entry Array. För närvarande pekar GPT-huvudet för säkerhetskopiering på säkerhetskopieringen av den matrisen. Den faktiska GPT-partitioneringsmatrisen bör finnas på LBA 2. Detta värde måste ändras till 0x0200000000000000.
När dessa tre värden har ändrats är det dags att beräkna CRC32-värdet.
Den resulterande kontrollsumman är:

Så nu kan vi ersätta 0x00000000-värdena vid offset 16 med 0xBC372C1B:
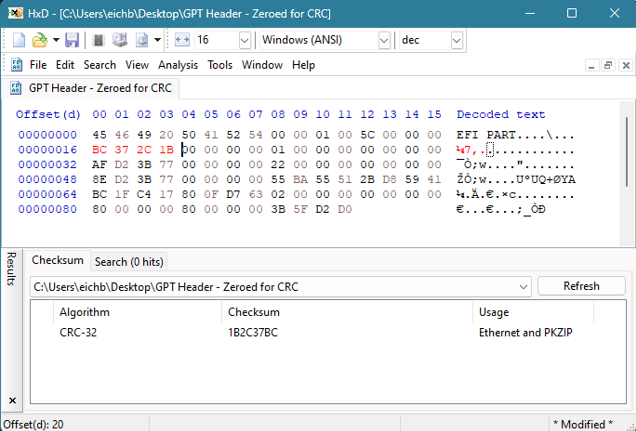
HxD har en CRC32-kontrollsummaberäknare inbyggd under Analys -> Kontrollsummor. Det resulterande värdet behöver bara läggas till som ett little-endian-värde.
Om vi av ren nyfikenhet skulle isolera dessa 512 byte för originalet och säkerhetskopian som vi återställde, matchar hashvärdena verkligen, vilket indikerar att vi framgångsrikt reproducerade den ursprungliga GPT Header med hjälp av säkerhetskopian.

Slutsats
Att förstå hur GPT-headern fungerar är viktigt för alla som arbetar med digital kriminalteknik, dataåterställning eller systemadministration. GPT-huvudet definierar inte bara diskens layout och struktur utan säkerställer även dataintegritet genom mekanismer som CRC32-kontrollsummor och säkerhetskopieringshuvuden. Genom att behärska detaljerna i GPT-huvudet är du bättre rustad att felsöka och reparera diskproblem, vilket säkerställer tillförlitligheten och tillgängligheten för kritiska data.
När vi fortsätter den här serien kommer vårt nästa fokus att vara på GPT Partition Table Entry Array. Vi kommer att utforska hur partitionsposter är strukturerade och hur de arbetar tillsammans med GPT Header för att upprätthålla organisationen och integriteten hos diskpartitioner. Håll ögonen öppna för en omfattande guide om att analysera och reparera GPT Partition Table Entry Array, vilket ger dig ytterligare kunskap att hantera GPT-partitionerade diskar med självförtroende.
Missade du del 1?
Börja från början: Förstå den skyddande MBR:en på GPT-partitionerade diskar (del 1) - där vi går igenom hur GPT säkerställer bakåtkompatibilitet med äldre system.
Är du redo för nästa steg?
Fortsätt till Del 3: Navigera i GPT-partitionens inmatningsfält - där vi undersöker hur partitionsposter är strukturerade och hur de kompletterar GPT Header.





2 svar
Fantastiska sidor (den och del 1).
Tack så mycket!