

I den første delen av denne bloggserien utforsket vi Protective MBR og dens rolle i å sikre at moderne GPT-partisjonerte disker er kompatible med eldre systemer. Vi gikk i dybden på hvordan Protective MBR fungerer som en barriere for å forhindre at eldre systemer feiltolker GPT-disker, og dermed sikrer at hele disken er merket som i bruk av GPT. Denne grunnleggende forståelsen danner grunnlaget for et dypdykk i selve hjertet av GUID-partisjonstabellen (GPT) - GPT-headeren.
I denne andre delen skal vi gå gjennom GPT Header, en viktig komponent i GPT-skjemaet som gir viktig informasjon om diskens struktur. Vi går gjennom hvert enkelt felt i GPT-headeren, forklarer dets betydning og hvordan det bidrar til diskens generelle funksjonalitet og integritet. Når dette innlegget er ferdig, vil du ha en omfattende forståelse av GPT-headeren, slik at du trygt kan analysere og manipulere GPT-partisjonerte disker i rettsmedisinske undersøkelser eller datagjenopprettingsscenarioer.
GPT (GUID Partition Table)-hodet er en viktig komponent i diskens partisjoneringssystem. Den deler disken inn i separate seksjoner, som hver kan lagre forskjellige typer data, for eksempel operativsystemet, personlige filer, programdata eller spill. Disse seksjonene kan være forskjellige stasjoner (for eksempel C:-stasjonen, D:-stasjonen, E:-stasjonen osv.).
GPT Header inneholder en sikkerhetskopi i enden av disken, på samme måte som å ha en ekstranøkkel til bibliotekskatalogen i tilfelle hovednøkkelen skulle gå tapt eller bli skadet. Dette sikrer at vi kan finne og få tilgang til dataene våre selv om noe skulle gå galt.
GPT-headeren angir plasseringen av sikkerhetskopien og plasseringen av GUID Partition Table Entry Array, som er en liste over GPT-partisjonsposter som angir hvor disse seksjonene (partisjonene) befinner seg på disken.
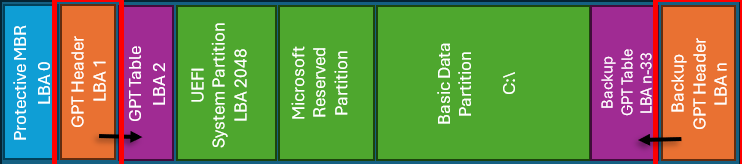
Figur 1: Oppsett av en hypotetisk Windows 10-installasjon med ett volum (n = siste sektor på stasjonen)
GPT Header starter med signaturen EFI PART. Resten av verdiene er fordelt i tabellen nedenfor:
GPT-headeren starter med signaturen "EFI PART". Resten av verdiene er fordelt i tabellen nedenfor:
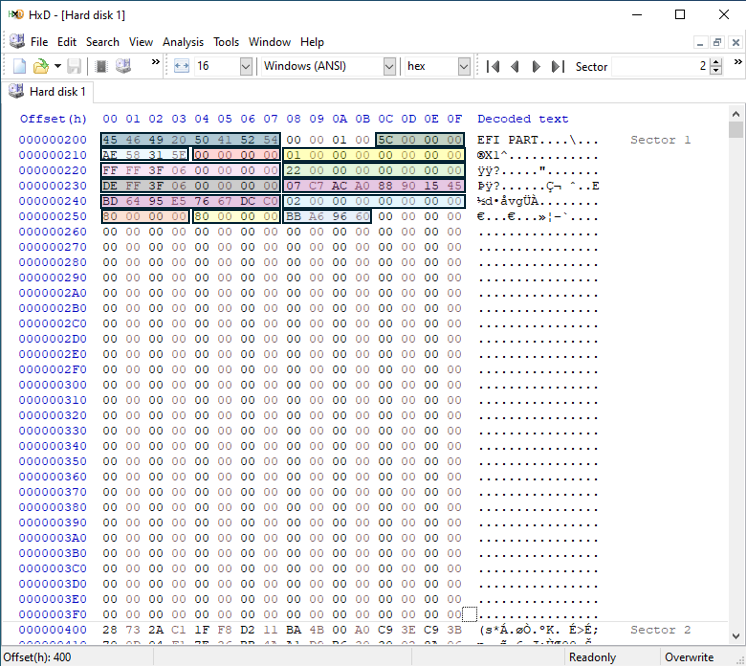
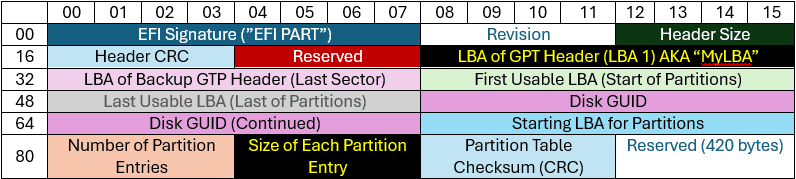
Kilde: https://uefi.org/specs/UEFI/2.10/05_GUID_Partition_Table_Format.html

Så langt vil de første 16 byte i GPT-headeren forbli konstant på tvers av ulike GPT-disker.
GPT-header CRC

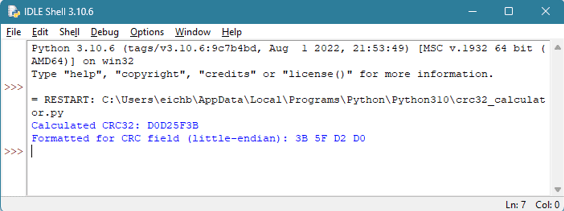
Nedenfor ser du et eksempel på hvordan du beregner CRC32 for GPT-toppteksten:
Du kan bruke et Python-skript til å beregne CRC for isolerte byte:

Python-skriptet finner du på : https://github.com/eichbaumj/Python

Python-skriptet tar den resulterende CRC32-verdien og konverterer den til formatet som kreves for GPT-headeren. Den beregnede verdien er i dette tilfellet 0x1B2C37BC. Men for å lagre den i feltet i GPT-headeren, leses verdien i little endian: 0xBC372C1B.


Skjermbildet nedenfor viser GUID uthevet i GPT-overskriften:

GUID-en er en heksadesimal verdi på 16 byte, men hvis du tror at du bare kan kopiere verdiene og skille dem fra hverandre med bindestreker og sette krøllparenteser rundt dem, tar du feil. Du ville ende opp med feil verdi.
Du kan se at HxD tilbyr GUID-konvertering i datainspektøren til høyre. Men hvordan skjer det? Hvordan skjer det?
55 BA 55 51 51 2B D8 59 41 BC 1F C4 17 80 0F D7 63
Bli det:
{5155BA55-D82B-4159-BC1F-C417800FD763}
XX XX XX XX XX | XX XX | XX XX | XX XX | XX XX | XX XX XX XX XX XX
55 BA 55 51 | 2B D8 | 59 41 | BC 1F | C4 17 80 0F D7 63
Det første settet med fire byte konverteres til little-endian hex: 51 55 BA 55
Det andre settet på 2 byte konverteres til little-endian hex: D8 2B
Det tredje settet på 2 byte konverteres til little-endian hex: 59 41
De to gjenværende settene med hex-verdier blir stående som de er, big-endian: BC 1F | C4 17 80 0F D7 63
Når alle konverteringene er fullført, kan vi sette dem sammen ved å plassere bindestreker der de skal være, og omslutte det hele med krøllete klammer:
{5155BA55-D82B-4159-BC1F-C417800FD763}
Vi kan bekrefte at dette er riktig koding av GUID-en ved å starte diskpart fra kommandolinjen og se etter diskens uniqueid:



Vi kan bruke det samme Python-skriptet, men erstatte hex-verdiene med de som finnes i Partition Entry Array.


Og vi kan se at verdien stemmer overens med det som finnes i GPT-headeren.
Ok, nå som vi vet hvordan GPT-headeren er strukturert og at det finnes en sikkerhetskopi i den siste sektoren på disken, hvordan går vi frem for å reparere GPT-headeren hvis den skulle bli ødelagt eller slettet?
For å reparere GPT Header kopierer du de siste 512 byte fra slutten av disken og limer dem inn i LBA 1 (sektor #2). Merk at det er nødvendig med noen få modifikasjoner.
Nedenfor ser du et eksempel på hvordan GPT-headeren for sikkerhetskopiering ser ut på slutten av en disk:
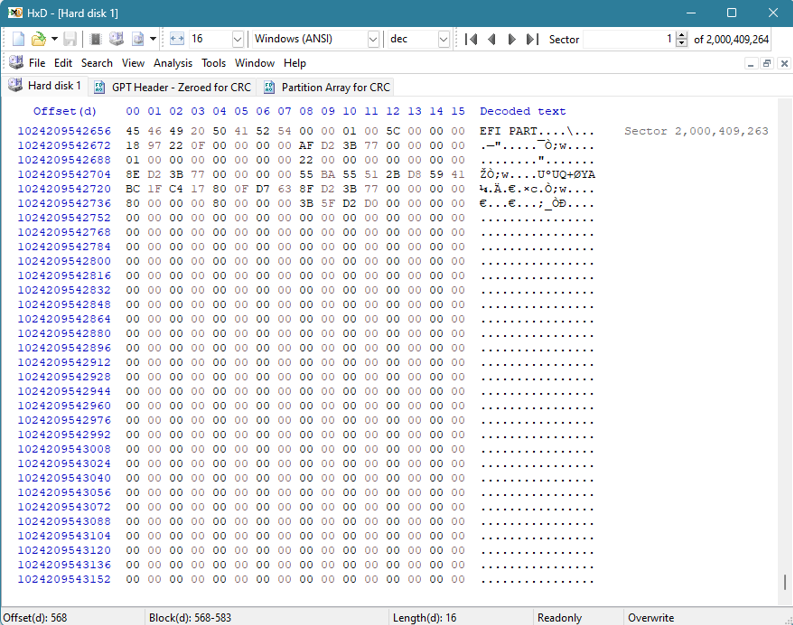
Vi kan se at noen verdier forblir konstante sammenlignet med den opprinnelige GPT Header. Disse konstantene er uthevet i rødt nedenfor:
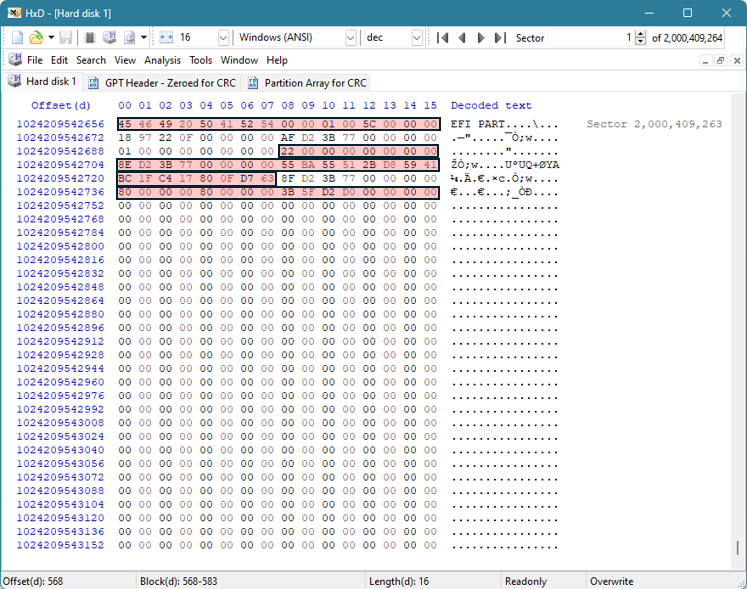
Det er fire verdier som må endres.
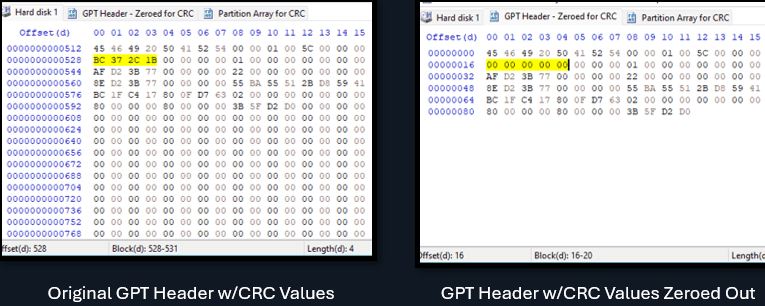
Den første er GPT Header CRC, som vi kommer tilbake til. Inntil videre kan disse verdiene nullstilles, ettersom vi må bruke CRC-en som er beregnet etter at vi har endret de andre verdiene, for å få den riktige CRC-en igjen.

Den neste er MyLBA-verdien som ligger på offset 24 i 4 byte. Denne verdien peker til plasseringen av GPT-headeren (der den befinner seg for øyeblikket), og den nåværende posisjonen er LBA 1 eller 0x010000000000000000000.

Verdien på 8 byte ved offset 32 er verdien som peker oss til plasseringen av GPT-headeren for sikkerhetskopien. Sikkerhetskopien peker for øyeblikket til originalen, men vi må endre denne verdien slik at den representerer den siste sektoren på disken. Dette skjedde med hex-verdiene som vi nettopp endret i forrige trinn. I dette eksemplet må verdien endres til 0xAFD23B7700000000.
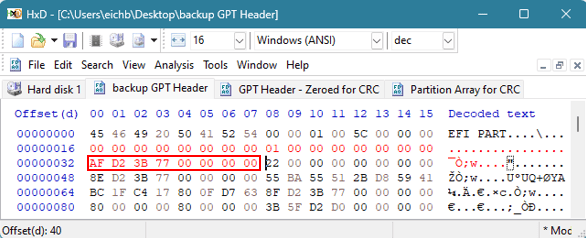
Verdien på 8 byte i offset 72 må gjenspeile plasseringen og starten på GPT Partition Entry Array. For øyeblikket peker sikkerhetskopien av GPT-toppteksten til sikkerhetskopien av denne matrisen. Den faktiske GPT-partisjonsmatrisen skal være på LBA 2. Denne verdien må endres til 0x02000000000000000000.
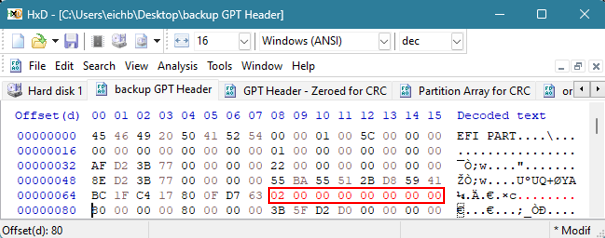
Når disse tre verdiene er endret, er det på tide å beregne CRC32-verdien.
Den resulterende sjekksummen er:

Så nå kan vi erstatte 0x00000000-verdiene ved offset 16 med 0xBC372C1B:
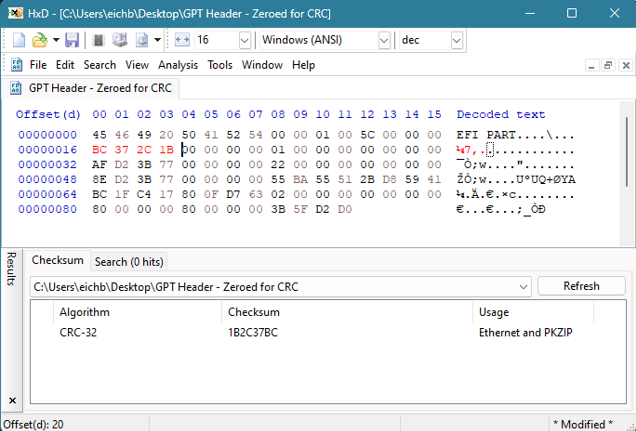
HxD har en innebygd CRC32-kontrollsumkalkulator under Analyse -> Kontrollsummer. Den resulterende verdien trenger bare å legges til som en little-endian-verdi.
Hvis vi for nysgjerrighetens skyld skulle isolere disse 512 byte for originalen og sikkerhetskopien som vi gjenopprettet, stemmer hashverdiene faktisk overens, noe som indikerer at vi klarte å reprodusere den opprinnelige GPT Header ved hjelp av sikkerhetskopien.

Det er viktig å forstå detaljene i GPT-headeren for alle som jobber med digital kriminalteknikk, datagjenoppretting eller systemadministrasjon. GPT-headeren definerer ikke bare diskens layout og struktur, men sikrer også dataintegritet ved hjelp av mekanismer som CRC32-sjekksummer og backup-header. Ved å beherske detaljene i GPT-headeren er du bedre rustet til å feilsøke og reparere diskproblemer, noe som sikrer påliteligheten og tilgjengeligheten til kritiske data.
I fortsettelsen av denne serien vil vi fokusere på GPT Partition Table Entry Array. Vi vil undersøke hvordan partisjonsoppføringer er strukturert og hvordan de fungerer sammen med GPT Header for å opprettholde organiseringen og integriteten til diskpartisjoner. Følg med for en omfattende guide om analyse og reparasjon av GPT Partition Table Entry Array, som gir deg ytterligere kunnskap til å håndtere GPT-partisjonerte disker på en trygg måte.
Gikk du glipp av del 1?
Begynn fra begynnelsen: Forstå den beskyttende MBR-en på GPT-partisjonerte disker (del 1) - der vi går gjennom hvordan GPT sikrer bakoverkompatibilitet med eldre systemer.
Er du klar for neste steg?
Fortsett til Del 3: Navigere i GPT-partisjonens oppføringstabell - hvor vi undersøker hvordan partisjonsoppføringene er strukturert og hvordan de utfyller GPT Header.




3-svar
Flotte sider (den og del 1).
Tusen takk!