

Nei post precedenti abbiamo gettato le basi per la comprensione della tabella delle partizioni GUID (GPT) esaminando l'MBR protettivo e l'intestazione GPT. Ora, nella terza parte, ci concentriamo sull'array di voci di partizione GPT. Questo componente cruciale dello schema GPT fornisce una mappa dettagliata di tutte le partizioni del disco; ogni voce contiene informazioni vitali su una partizione specifica. Comprendendo la struttura e la funzione del GPT Partition Entry Array, si otterrà una visione completa di come GPT gestisce le partizioni, consentendo analisi, risoluzione dei problemi e recupero dei dati più efficaci.
L'array di voci della tabella di partizione GUID (GPT) è una parte fondamentale del sistema di partizionamento GPT, utilizzato per definire e gestire le partizioni su un disco rigido. È un elenco dettagliato che registra le specifiche di ogni partizione sul disco, come il catalogo di una biblioteca che elenca i dettagli di ogni libro.
GUID della partizione: Ogni partizione ha un identificatore unico, noto come GUID della partizione, che garantisce che ogni partizione possa essere identificata in modo univoco, anche su sistemi diversi.
ID univoco: Si tratta di un altro identificatore unico specifico per ogni partizione, che fornisce un ulteriore livello di identificazione univoca.
Avvio dell'LBA (Logical Block Addressing) della partizione: Indica il punto di partenza della partizione sul disco. Indica al sistema dove inizia la partizione.
LBA finale della partizione: Come l'LBA iniziale, indica il punto in cui termina la partizione sul disco.
Bit di attributo: Si tratta di flag che forniscono informazioni aggiuntive sulla partizione, ad esempio se è avviabile o se ha attributi speciali.
Nome della partizione: Ogni partizione può avere un nome leggibile dall'uomo, che facilita l'identificazione dello scopo o del contenuto della partizione. Questo nome termina con un carattere null per indicare la fine della stringa.
Analizziamo tutti questi elementi in dettaglio, in modo da comprendere appieno ogni voce dell'array.


Quando il disco è configurato come disco GPT, la prima partizione che viene creata è la partizione di sistema EFI (ESP). Si tratta di una partizione nascosta non facilmente accessibile agli utenti. Questa partizione si trova nel settore 2048 ed è formattata come FAT32 per la compatibilità con tutti i sistemi (Windows, Linux, MacOS).
L'immagine qui sopra mostra un'installazione standard di Windows 10 in cui è stata creata la partizione riservata Microsoft e una partizione dati di base specificata dall'utente durante l'installazione.

Di seguito è riportato un estratto dei GUID da una tabella che si trova nella pagina di Wikipedia GUID Partition Table:

Fonte: https://en.wikipedia.org/wiki/GUID_Partition_Table#Partition_type_GUIDs
Naturalmente, il GUID non verrà memorizzato nel modulo GUIID quando si visualizzano i valori nel visualizzatore esadecimale.

I GUID vengono convertiti proprio come nel precedente post, ma possono essere facilmente visualizzati in HxD:

È possibile confermare i GUID della partizione del volume con il comando: mountvol.exe


Conoscendo l'LBA iniziale e l'LBA finale, è possibile calcolare la dimensione della partizione. Ad esempio, la partizione EFI:
LBA iniziale: 2048
Fine LBA: 534527
Lunghezza totale: 532479 settori x 512 byte/settore = 272629248 byte, pari a 260 MB.


L'array di inserimento della partizione GPT di backup si trova alla fine del disco e prima dell'intestazione GPT, in particolare 33 settori prima della fine del disco (LBA (n - 33) dove n è l'ultimo settore del disco). Possiamo anche fare qualche calcolo per capire perché si trova 33 settori prima della fine del disco o 32 settori prima dell'intestazione GPT di backup.
Ogni voce della partizione è di 128 byte e ci sono 128 voci totali nell'array di voci. Ciò significa che ci sono 16.384 settori nell'array o 32 settori (16384/512).
L'intestazione GPT di backup punta alla posizione della matrice di voci della partizione GPT di backup.


Backup della partizione GPT Entrata nell'array vicino alla fine del disco
Per riparare l'array di voci della partizione GPT è sufficiente copiare il backup di 16.384 byte trovato in 33 settori dalla fine del disco e incollarlo negli LBA da 2 a 3. Non è necessario alterare/modificare i valori esadecimali perché si tratta di copie esatte. Non è necessario alterare/modificare i valori esadecimali, poiché si tratta di copie esatte.
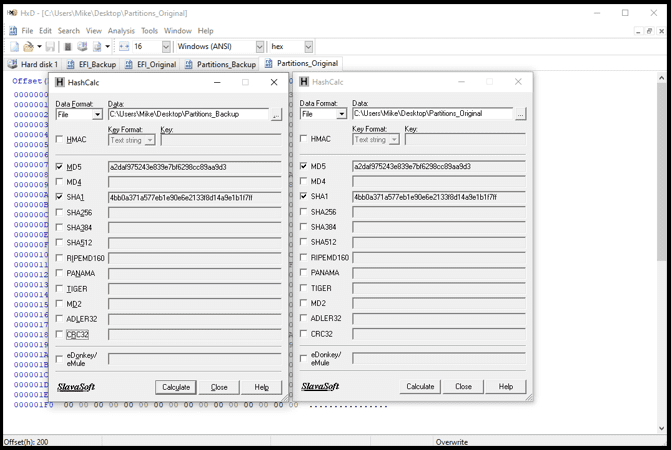
Il GPT di backup, situato alla fine del disco, è identico a quello primario. Infatti, ritagliando i settori per ciascuno di essi e facendo l'hashing, si nota che corrispondono esattamente.
In questa terza puntata abbiamo esaminato a fondo l'array di voci di partizione GPT, un componente fondamentale dello schema GPT. Analizzando ogni campo delle voci di partizione, dai GUID ai bit degli attributi e ai nomi delle partizioni, abbiamo visto come GPT fornisca una struttura robusta per organizzare e accedere ai dati del disco. Queste conoscenze sono essenziali per le indagini forensi, per il recupero dei dati e per l'amministrazione del sistema, in quanto forniscono le competenze necessarie per navigare e manipolare efficacemente i dischi con partizioni GPT. Rimanete sintonizzati per il prossimo post, in cui approfondiremo le applicazioni pratiche e i casi di studio, portando la teoria nella pratica.
Questo post conclude la nostra serie di 3 parti sulle strutture di partizione GPT.
Se vi siete persi i post precedenti, iniziate con Parte 1 - L'MBR protettivoin cui esploriamo il modo in cui viene mantenuta la compatibilità con il legacy e continuiamo con Parte 2 - L'intestazione GPTche definisce il layout del disco e ne garantisce l'integrità.
Volete approfondire? Iscrivetevi alla nostra newsletter per ricevere i prossimi contenuti sul recupero delle partizioni, sull'hashing a livello di disco e sulle sfide CTF basate su scenari forensi reali.




3 risposte